
In recent years, it has been interesting to see how computing and storage have become separated to handle bigger scales.
For a very long period, file-and block-based storage is what the industry has been using.
The overhead of bookkeeping on the things-as metadata, inodes, or file information-is heavy for the computer that controls the file system.
To overcome this, a new way of storage has taken favor, generally known as “object-based storage”.
With it, each file is given an “object ID” for easy locating and keeping track of it besides that part of the metadata is dealt with by another computer, “metadata server.”
Object Storage represents the modern system of data storage developed to meet the demanding requirements of handling huge volumes of unstructured data, such as videos, images, and backups.
In this article, we are going to take a closer look at how object storage works; most importantly, its architecture and the complete working mechanism it is based on.
Table of contents
What is Object Storage?
Object storage is an organization and management methodology whereby data gets chunked down into small units, called objects.
Each object would contain the actual data itself, some extra information describing it-known as metadata-and a unique ID that identifies it.
Unlike traditional folder-and-file-based file systems, object storage keeps data in flat organizations without hierarchies.
This makes the management and scalability of huge amounts of data much easier.
Key Components of Object Storage
The three main elements at the core of Object Storage are:
- Objects: These would be the base units of data storage, which could be a text file, a media file, or even a database record.
- Metadata: This is information that describes what’s inside each object, making it easier to search for and organize the data.
- Unique Identifiers: Each object has a special ID, like a “name tag,” that makes it easy to find and retrieve, without needing to follow folder paths or file systems.
The Evolution of Object Storage
Object storage started in the early 1990s when businesses needed storage that could grow and adapt more easily.
Traditional storage methods, like file and block storage, couldn’t manage the increasing amount of unstructured data that came with the growth of the internet.
The Shift from Traditional Storage Systems
Traditional storage systems, like file storage, arrange data in a hierarchy with folders and subfolders.
Block storage splits data into smaller pieces, stored in different blocks on a server.
In contrast, object storage uses a flat structure and treats each piece of data as a separate object, making it easier to scale and manage data more efficiently
Importance of Object Storage in Modern Data Management
With more than 80% of organizational data being unstructured, the need for efficient storage solutions has never been greater.
Object storage provides a scalable, cost-effective solution that can handle massive datasets without compromising on accessibility or performance.
Architecture of Object Storage
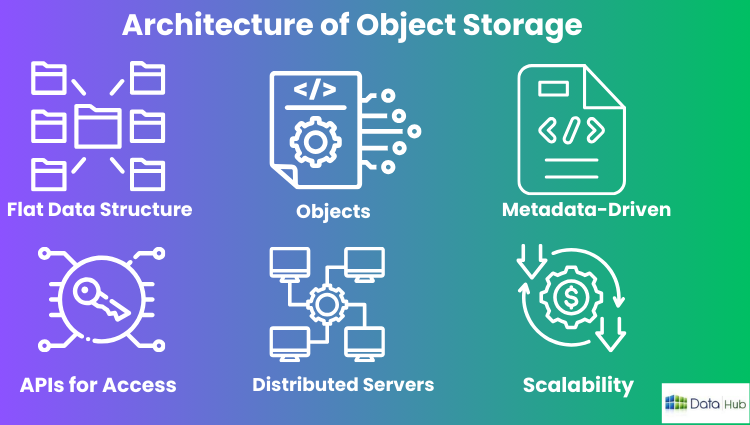
Object storage is very different from traditional architectures for storage, such as file and block storage.
A breakdown of some of the key architectural elements follows:
1. Flat Data Structure:
Object storage doesn’t require a hierarchy, unlike file storage.
As such, it stores data as distinct objects, rather than as files in folders or as blocks on disks.
2. Objects:
All data is divided into objects: a video file, an image, etc. Each object has three parts:
- Data: Data refers to the actual content you are storing. For instance, in video files this would include images and audio. When dealing with image files it can simply be the picture itself – in short it represents what you want to preserve for later use.
- Metadata: Metadata serves as a label that describes its contents and uses. Metadata includes details such as what type of file (video, image or document), its creation date and who can access or edit it – information which enables us to comprehend content without actually opening it; for instance a photo’s metadata might show when and which camera type was used when taking it.
- Unique Identifier: Every object has an identifier, which serves as a special code or name that helps quickly and efficiently find its location. Like how library books each an individual number for easy searching have, video files may feature ID numbers like “123ABC,” making retrieving videos even if multiple files exist in the same system easier.
3. Metadata-Driven:
While the file systems manage files against file paths, object storage describes data through metadata.
It is extensive metadata that allows the system to efficiently search for, organize, and retrieve the data using its attributes.
4. Distributed Servers:
Object storage spans a number of servers or even locations to store data.
That’s what object storage can assure redundancy, availability, and scalability.
Object storage is capable of handling large-scale environments, such as cloud storage.
5. APIs for Access:
Object storage very often employs an API to enable applications to speak to the storage system.
Of course, one of the most common APIs is that of Amazon S3, which enables seamless fetching and management of data across platforms.
6. Scalability:
Object storage allows horizontal scalability, where servers or storage nodes can be added as needed.
The system will handle growing amounts of data without any complex restructuring.
Complete Working Mechanism of Object Storage
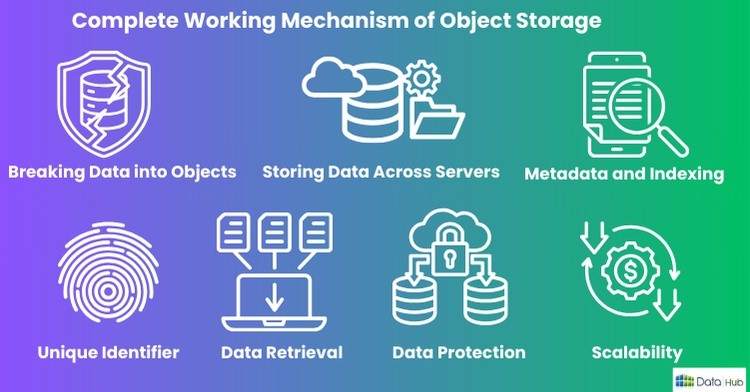
Now, let me explain the process of object storage from the very moment data are uploaded to how it is retrieved.
1. Breaking Data into Object:
When you upload data into an object storage system, the data gets divided into objects. Each object contains the data itself, with metadata and a unique identifier.
2. Storing Data Across Servers:
After the data is broken into objects, it is distributed across multiple servers or nodes.
This ensures that no single point of failure exists in the system, as data is duplicated across different locations.
Once shard into objects, the data will be divided across multiple servers or nodes.
Consequently, there is no single point of failure, and data will be duplicated in different locations.
3. Metadata and Indexing:
The metadata about the objects becomes really important for use in the way the system will store and retrieve the data. Metadata can include but is not limited to:
- Object size
- Date of creation
- Data format: image, video, document
- Access permissions
This metadata allows the creation of an index to impact efficient and fast search for voluminous data.
4. Unique Identifier for Easy Retrieval:
Every object will have an identifier, like a barcode on data.
During retrieval, you wouldn’t have to know where exactly it is physically located or even the folder hierarchy that is in.
Just give it the identifier, and it fetches data from wherever it is kept.
5. Data Retrieval via APIs:
Object storage retrieves or manages data by APIs.
If the application has requested a file to be used, it will send a request via API that will translate into the system to locate and retrieve the object using its unique identifier.
6. Redundancy and Data Protection:
Object storage systems often replicate objects across various storage nodes to make sure data is safeguarded and always available.
This level of redundancy is the insurance against hardware failure, data corruption, or any other kind of data loss incident.
7. Data Scalability:
Object storage is inherently scalable, since as more data arrives, the system automatically can distribute new objects across additional servers with an efficient and balanced load distribution.
Object storage is therefore apt for massive volumes of data such as IoT data, videos, and backup data.
Why Choose DataHub Nepal?
If you are searching for a trusted hosting provider, DataHub Nepal will be an excellent one. Here is why:
- Local Support: Being in Nepal, they understand local business and support them efficiently with quick, personalized support.
- Fast Servers: They use high-speed servers to ensure that your website loads faster, which improves user experience and SEO.
- Affordable Plans: They have pricing plans to suit every budget, from a small startup to enterprise-scale businesses.
- Scalable Solution: As your business grows, so can their hosting for you.
- 24/7 Customer Support: If an issue comes up, around the clock, they can be contacted.
- Strong Security: Advanced security measures and backups mean that with them, your website will be secure.
- Latest Technology: Speed with SSD storage and enhanced DDoS protection against attacks.
- 99.9% Uptime: Your site will be online almost always, saving costly downtime.
- Eco-friendly: DataHub Nepal cares for the environment with energy-efficient systems.
In short, DataHub Nepal provides reliable, secure, and fast hosting for excellent support and competitive pricing that goes with your aim of online success.
Conclusion
Object storage is highly scalable, flexible, and cost-effective, with its major usage in unstructured data storage.
Architecture, utilizing objects, metadata, and a unique identifier, makes data retrieval at any given time highly accessible through horizontal scalability and redundancy.
Object storage fits perfectly for modern businesses dealing with high volumes of data, including media companies, cloud service providers, and enterprises that need long-term, reliable storage.
Object storage is differentiated from the traditional systems of storage by a mechanism that is essentially about breaking data into objects, use of metadata for indexing, and APIs for easy access.
FAQ
Object storage can store any type of unstructured data such as images, videos, documents, or backups.
It replicates objects over many nodes to protect against hardware failure.
Yes! As long as you have access to the internet, you will be able to pull your objects from anywhere.
Of course! Scalability allows businesses to start small and grow as needed.
It normally makes use of HTTP/HTTPS in addition to RESTful APIs for efficient access.